УЧЕНЫЕ ВОСПРОИЗВЕЛИ БЕЗЗВУЧНУЮ РЕЧЬ ПО АКТИВНОСТИ МОЗГА
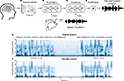
Американские ученые и инженеры разработали прототип инвазивного устройства-декодера, позволяющего синтезировать речь по активности мозга при движении органов речевого тракта — причем в одном эксперименте им удалось воспроизвести беззвучную речь, хотя и с потерей качества. В будущем на основе этого прототипа можно будет создавать новые нейрокомпьютерные интерфейсы, говорится в статье, опубликованной в журнале Nature.
Нейрокомпьютерные интерфейсы позволяют считывать и обрабатывать данные об активности головного мозга, они, среди прочего, применяются для помощи пациентам с потерей речи, но пока им доступны в основном приборы, позволяющие управлять курсором с помощью движений головы или глаз, которые работают достаточно медленно по сравнению с обычной речью. В начале года в Scientific Reports вышла статья, авторам которой удалось обучить алгоритм воссоздавать речь из мозговой активности человека при ее прослушивании. Для этого они использовали активность аудиторной коры, полученной с помощью электродов, вживленных в мозг пациентов с эпилепсией, при прослушивании отдельных цифр, а затем синтезировали на ее основе короткие фразы. Получившаяся речь оказалась разборчивой в 75 процентах случаев.
Группа под руководством Эдварда Ченга (Edward Chang) из Калифорнийского университета в Сан-Франциско предложила свой метод синтеза речи по мозговой активности при движении челюсти, гортани, губ и языка. По их словам, этот двухэтапный метод (распознавания активности мозга, связанной с движением органов речи, и трансформации этих сигналов в слова) сейчас позволяет точнее синтезировать речь, чем если бы добровольцы, к примеру, думали о заданных словах или даже просто предметах, хотя такие методы тоже интересуют ученых.
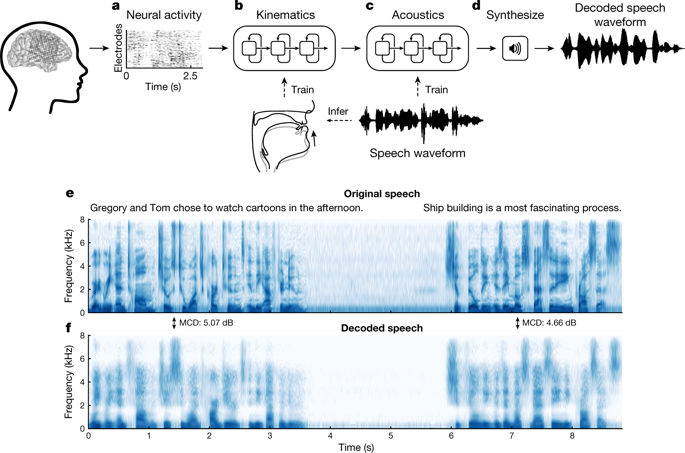
Сначала исследователи с помощью электрокортикографа записывали сигналы коры головного мозга у пятерых свободно говорящих добровольцев с эпилепсией, которые произносили вслух несколько сотен предложений. Эти предложения были специально подобраны так, чтобы воспроизводить весь спектр типичной для английского языка активности речевого тракта. При этом авторы исследования считают, что их прототип вполне сможет работать и с другими языками при предварительном обучении на соответствующем языковом материале.
Они обучили одну рекуррентную нейронную сеть распознавать в активности вентральной сенсомоторной коры, верхней височной извилины и нижней лобной извилины элементы движения речевого тракта, а вторую сеть — распознавать в них акустические параметры речи, исходя из которых она затем синтезировалась.
Типичный нейрокомпьютерный интерфейс позволяет синтезировать примерно 5-10 слов в минуту в зависимости от скорости набора текста, тогда как прототип ученых работает на привычной скорости речи в 120-150 слов в минуту для английского языка.
Ученым удалось синтезировать речь и на основе сигналов от «немых» движений, хотя ее качество было хуже. На телефонном пресс-брифинге Ченг, в частности, отметил, что в будущем они видят работу нейрокомпьютерного интерфейса на основе их прототипа именно так: человек активно пытается произнести слова — даже если он, к примеру, парализован, мозг все равно отправляет соответствующие сигналы органам речевого тракта — и машина, обученная на активности чужого мозга, синтезирует речь. При этом Чанг подчеркнул, что речь идет только о распознавании устной речи, но не мысленной, то есть внутренней речи, как бы интенсивно человек ни думал о словах.
Источник: https://nplus1.ru/news/2019/04/24/brain-to-speech